Analyzing Quantum Programs with LintQ: A Static Analysis Framework for Qiskit
In Research Papers of the ACM International Conference on the Foundations of Software Engineering (FSE ’24).
As quantum computing is rising in popularity, the amount of quantum programs and the number of developers writing them are increasing rapidly. Unfortunately, writing correct quantum programs is challenging due to various subtle rules developers need to be aware of. Empirical studies show that 40-82% of all bugs in quantum software are specific to the quantum domain. Yet, existing static bug detection frameworks are mostly unaware of quantum-specific concepts, such as circuits, gates, and qubits, and hence miss many bugs. This paper presents LintQ, a comprehensive static analysis framework for detecting bugs in quantum programs. Our approach is enabled by a set of abstractions designed to reason about common concepts in quantum computing without referring to the details of the underlying quantum computing platform. Built on top of these abstractions, LintQ offers an extensible set of ten analyses that detect likely bugs, such as operating on corrupted quantum states, redundant measurements, and incorrect compositions of sub-circuits. We apply the approach to a newly collected dataset of 7,568 real-world Qiskit-based quantum programs, showing that LintQ effectively identifies various programming problems, with a precision of 91.0% in its default configuration with the six best performing analyses. Comparing to a general-purpose linter and two existing quantum-aware techniques shows that almost all problems (92.1%) found by LintQ during our evaluation are missed by prior work. LintQ hence takes an important step toward reliable software in the growing field of quantum computing.
[paper]
[open access paper]
[code and dataset]

Fuzz4All: Universal Fuzzing with Large Language Models
In Research Papers of IEEE/ACM International Conference on Software Engineering (ICSE ’24).
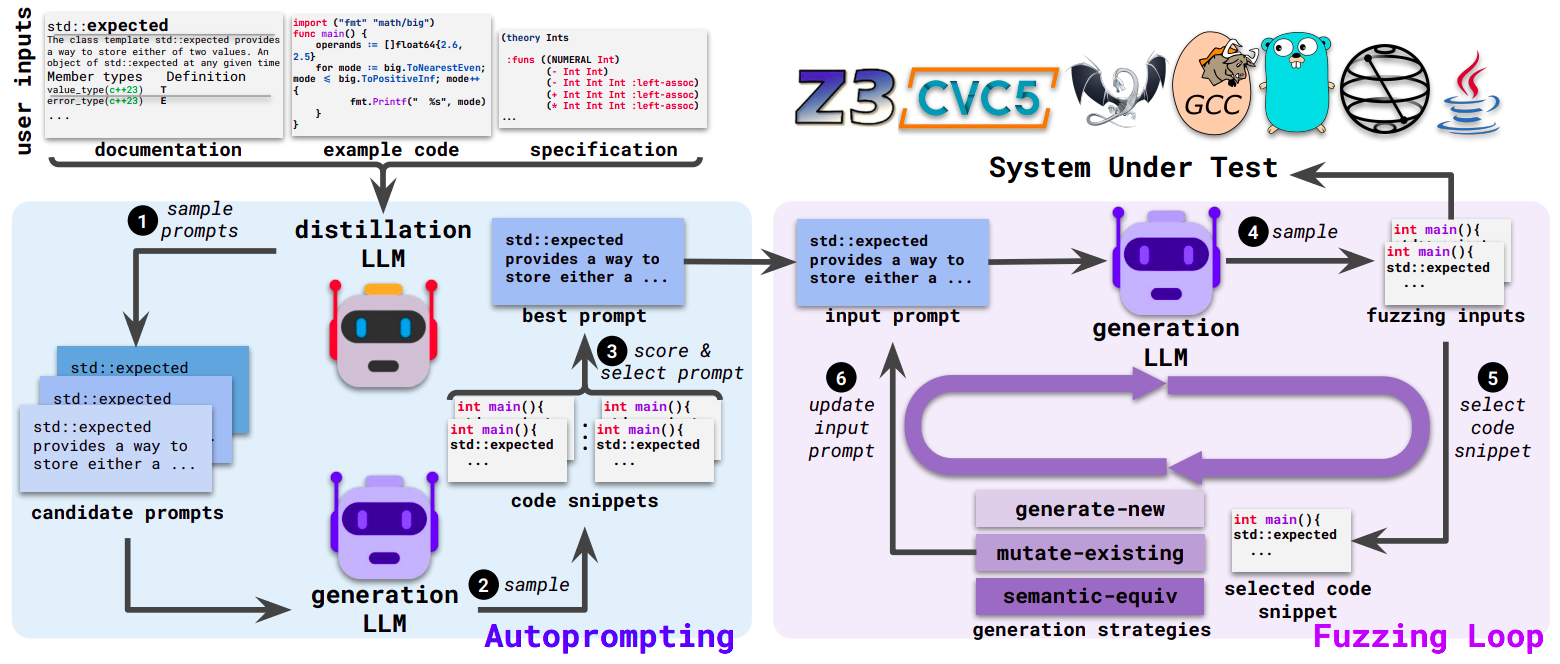
Fuzzing has achieved tremendous success in discovering bugs and vulnerabilities in various software systems. Systems under test (SUTs) that take in programming or formal language as inputs, e.g., compilers, runtime engines, constraint solvers, and software libraries with accessible APIs, are especially important as they are fundamental building blocks of software development. However, existing fuzzers for such systems often target a specific language, and thus cannot be easily applied to other languages or even other versions of the same language. Moreover, the inputs generated by existing fuzzers are often limited to specific features of the input language, and thus can hardly reveal bugs related to other or new features. This paper presents Fuzz4All, the first fuzzer that is universal in the sense that it can target many different input languages and many different features of these languages. The key idea behind Fuzz4All is to leverage large language models (LLMs) as an input generation and mutation engine, which enables the approach to produce diverse and realistic inputs for any practically relevant language. To realize this potential, we present a novel autoprompting technique, which creates LLM prompts that are wellsuited for fuzzing, and a novel LLM-powered fuzzing loop, which iteratively updates the prompt to create new fuzzing inputs. We evaluate Fuzz4All on nine systems under test that take in six different languages (C, C++, Go, SMT2, Java, and Python) as inputs. The evaluation shows, across all six languages, that universal fuzzing achieves higher coverage than existing, language-specific fuzzers. Furthermore, Fuzz4All has identified 98 bugs in widely used systems, such as GCC, Clang, Z3, CVC5, OpenJDK, and the Qiskit quantum computing platform, with 64 bugs already confirmed by developers as previously unknown.
[paper]
[website]
MorphQ: Metamorphic Testing of the Qiskit Quantum Computing Platform
In Research Papers of IEEE/ACM International Conference on Software Engineering (ICSE ’23).
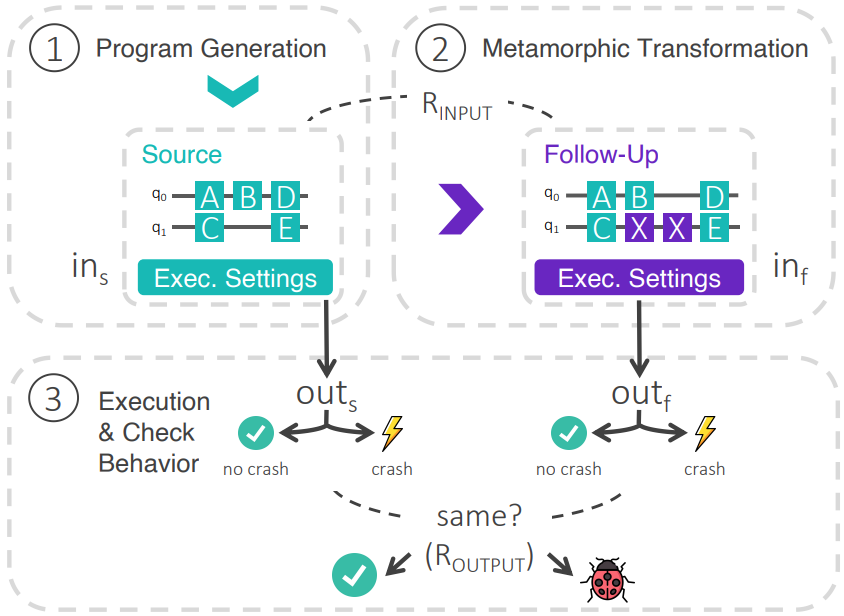
As quantum computing is becoming increasingly popular, the underlying quantum computing platforms are growing both in ability and complexity. Unfortunately, testing these platforms is challenging due to the relatively small number of existing quantum programs and because of the oracle problem, i.e., a lack of specifications of the expected behavior of programs. This paper presents MorphQ, the first metamorphic testing approach for quantum computing platforms. Our two key contributions are (i) a program generator that creates a large and diverse set of valid (i.e., non-crashing) quantum programs, and (ii) a set of program transformations that exploit quantum-specific metamorphic relationships to alleviate the oracle problem. Evaluating the approach by testing the popular Qiskit platform shows that the approach creates over 8k program pairs within two days, many of which expose crashes. Inspecting the crashes, we find 13 bugs, nine of which have already been confirmed. MorphQ widens the slim portfolio of testing techniques of quantum computing platforms, helping to create a reliable software stack for this increasingly important field.
[paper]
[dataset and code]
Bugs in Quantum Computing Platforms: An Empirical Study
In Research Papers of ACM Conference on Object Oriented Programming Systems Languages and Applications (OOPSLA ’22).
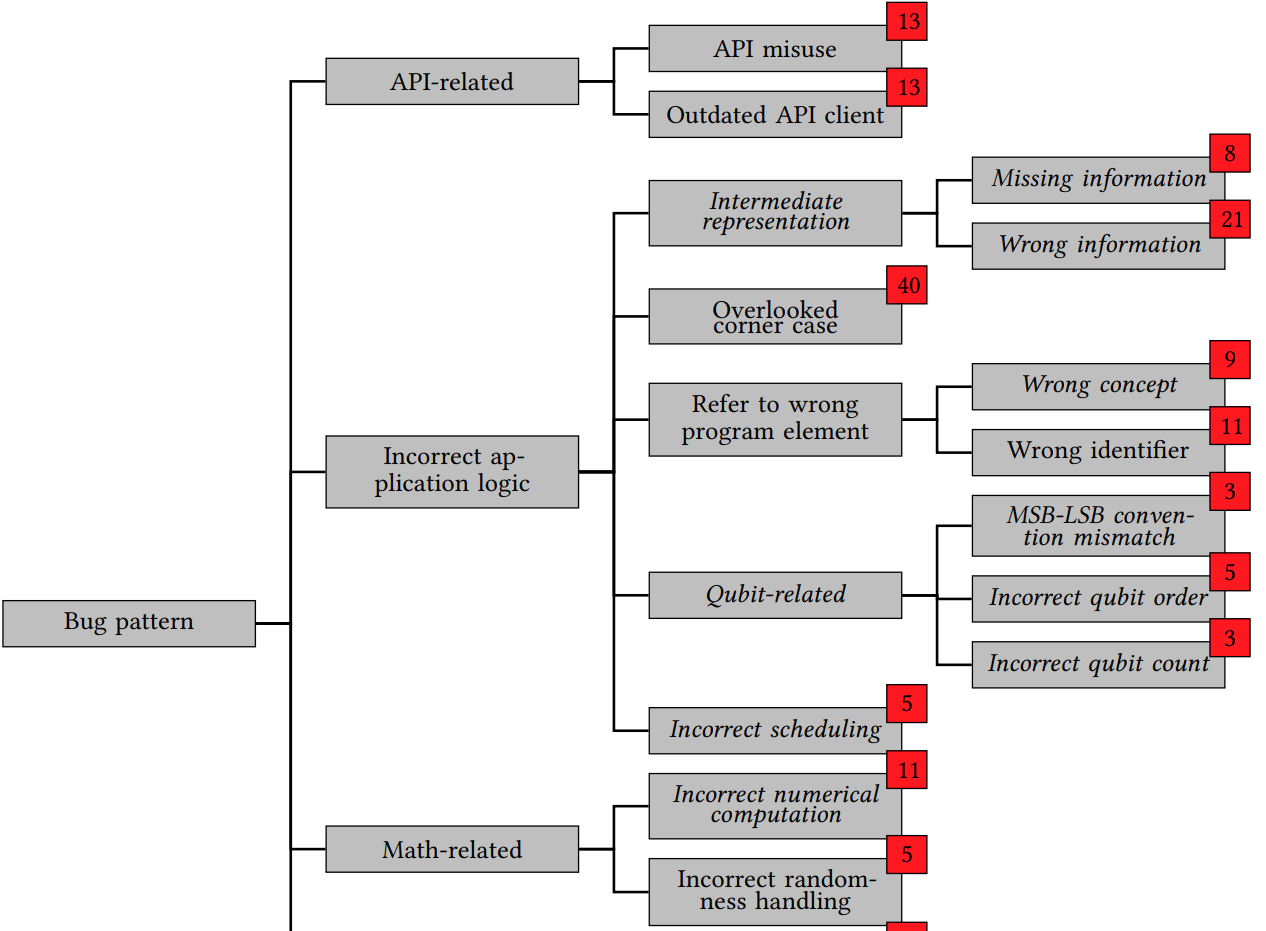
The interest in quantum computing is growing, and with it, the importance of software platforms to develop quantum programs. Ensuring the correctness of such platforms is important, and it requires a thorough understanding of the bugs they typically suffer from. To address this need, this paper presents the first in-depth study of bugs in quantum computing platforms. We gather and inspect a set of 223 real-world bugs from 18 open-source quantum computing platforms. Our study shows that a significant fraction of these bugs (39.9%) are quantum-specific, calling for dedicated approaches to prevent and find them. The bugs are spread across various components, but quantum-specific bugs occur particularly often in components that represent, compile, and optimize quantum programming abstractions. Many quantum-specific bugs manifest through unexpected outputs, rather than more obvious signs of misbehavior, such as crashes. Finally, we present a hierarchy of recurrent bug patterns, including ten novel, quantum-specific patterns. Our findings not only show the importance and prevalence bugs in quantum computing platforms, but they help developers to avoid common mistakes and tool builders to tackle the challenge of preventing, finding, and fixing these bugs.
[paper]
[dataset and code]
Thinking Like a Developer? Comparing the Attention of Humans with Neural Models of Code
In Research Papers of IEEE/ACM International Conference on Automated Software Engineering (ASE ’21).
Neural models of code are successfully tackling various prediction tasks, complementing and sometimes even outperforming traditional program analysis. While most work focuses on end-to-end evaluations of such models, it often remains unclear what the models actually learn, and to what extent their reasoning about code matches that of skilled humans. A poor understanding of the model reasoning risks deploying models that are right for the wrong reason, and taking decisions based on spurious correlations in the training dataset. This paper investigates to what extent the attention weights of effective neural models match the reasoning of skilled humans. To this end, we present a methodology for recording human attention and use it to gather 1,508 human attention maps from 91 participants, which is the largest such dataset we are aware of. Computing human-model correlations shows that the copy attention of neural models often matches the way humans reason about code (Spearman rank coefficients of 0.49 and 0.47), which gives an empirical justification for the intuition behind copy attention. In contrast, the regular attention of models is mostly uncorrelated to human attention. We find that models and humans sometimes focus on different kinds of tokens, e.g., strings are important to humans but mostly ignored by models. The results also show that human-model agreement positively correlates with accurate predictions by a model, which calls for neural models that even more closely mimic human reasoning. Beyond the insights from our study, we envision the release of our dataset of human attention maps to help understand future neural models of code and to foster work on human-inspired models.
[paper]
[dataset and code]

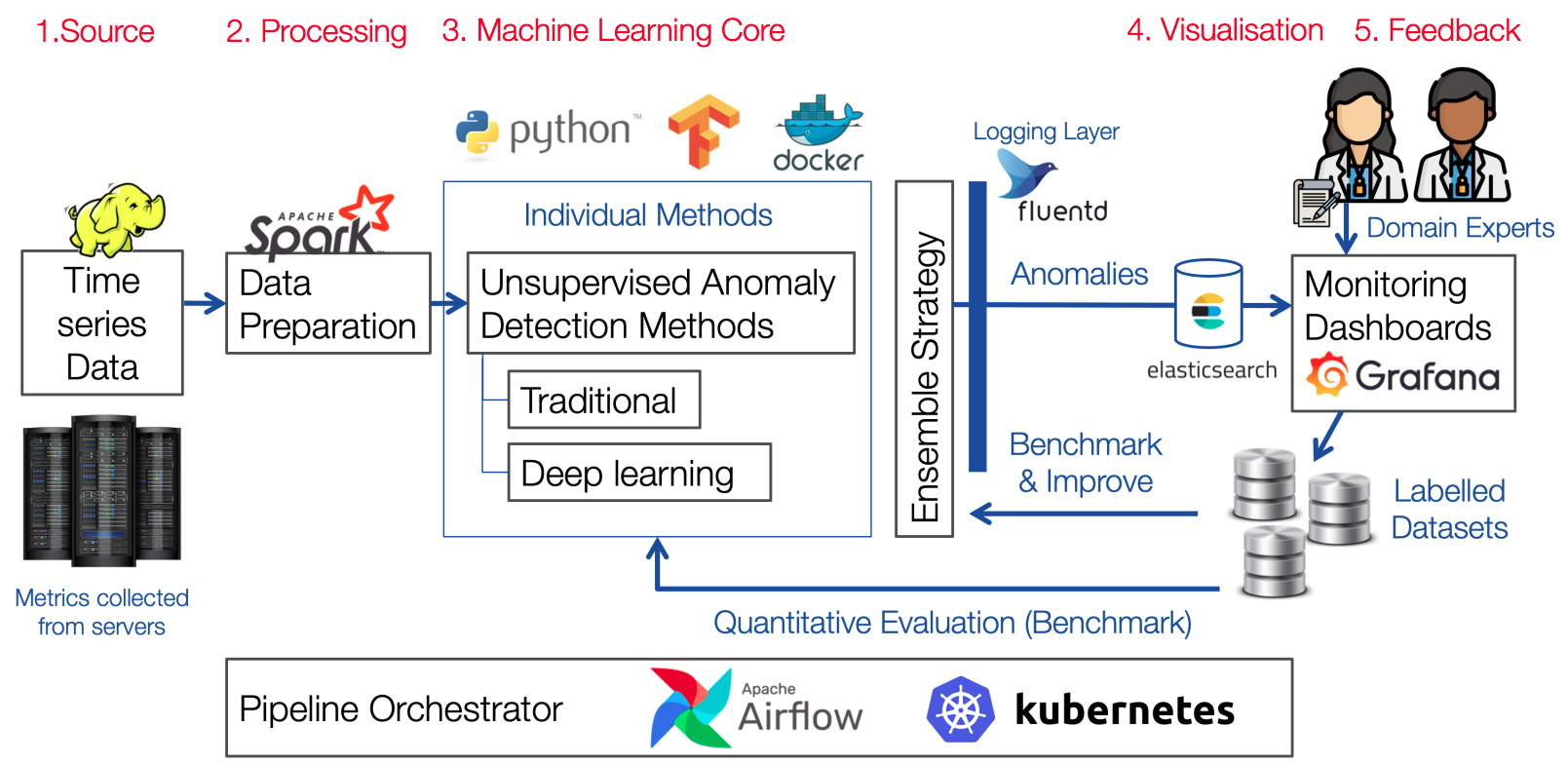
Time Series Anomaly Detection for CERN Large-Scale Computing Infrastructure
In CERN Document Server (CERN ’20).
Detecting anomalies in the CERN Data Center poses challenges due to its extensive computing infrastructure and vast data volume. Presently, anomaly spotting hinges on threshold-based alarms established by managers for performance metrics time series of each component. This study aims to simplify this intricate task by exploring automated machine learning solutions for anomaly detection. We primarily focus on unsupervised methods, considering both traditional and modern deep anomaly detection approaches. We propose novel time series-specific techniques and adapt traditional and deep learning methods for time series data, evaluating them using a comparative analysis. This research showcases the strengths of traditional methods for the specific CERN use case while highlighting deep methods’ effectiveness for complex normal instance patterns. Additionally, we establish an annotation system to efficiently label time series data and offer two new datasets for anomaly detection. Alongside our study, we release an open-source proof-of-concept anomaly detection system.
[master thesis]
[code]